

Was ist Cloud Computing?
Eine vereinfachte Definition von Cloud Computing ist Rechenleistung, die als Online-Dienst bereitgestellt wird. Je nach Bedarf kann bei einem Cloud-Dienstleister Hardware (Infrastructure as a Service, IaaS), eine Plattform (Platform as a Service, PaaS) oder direkt vorkonfigurierte Software (Software as a Service, SaaS) gemietet werden. Diese Lösungen sind insbesondere bei schwankendem Speicherbedarf oder wenn die Anschaffung eigener Hard-/Software vermieden werden soll, von Vorteil. Ein gutes Beispiel sind Anbieter von Online-Speicher- und Dateiverwaltungsdiensten. Google Drive ist beispielsweise ein solcher Dienst. Hier werden Dateien nicht auf physischen Geräten gespeichert, sondern „in der Cloud“. In industriellen Anwendungen könnten diese Daten, die in vielen Formen vorliegen, von IoT-Sensoren stammen. Sie können an einen Cloud-Dienst wie Microsoft Azure gesendet werden. Dazu müssen die Daten von den physischen Geräten im Feld in die Cloud übertragen werden. Hier kommen Edge Computing und Fog Computing ins Spiel.
Einblick und Beispiel Edge Computing
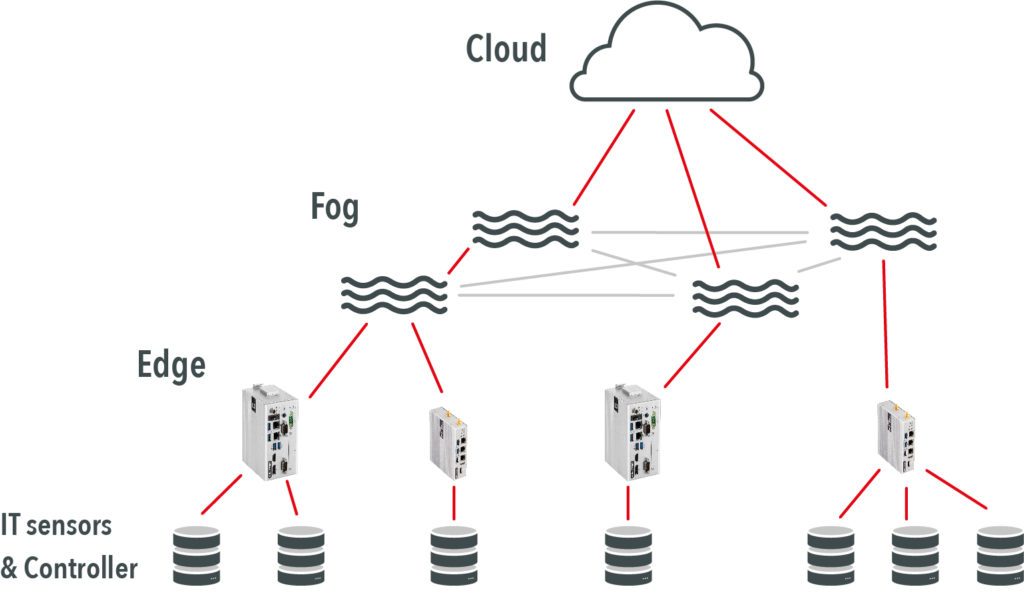
Im Gegensatz zu Fog Computing findet Edge Computing direkt am Endgerät, also am äußersten Rand des Netzwerks statt. Beim Edge Computing werden die Daten der angeschlossenen Sensoren gesammelt, gefiltert, komprimiert, ggf. verschlüsselt und weitergeleitet. Zur Vorverarbeitung am Endgerät können sogenannte IoT Edge Gateways eingesetzt werden. Beim Einsatz von Edge Gateways kann im Gegensatz zu integrierten Lösungen die Lebensdauer der angeschlossenen Sensoren bzw. die Akkulaufzeit verlängert werden, da aufwendige Analysen ausgelagert werden. Ein Beispiel für einen sinnvollen Einsatz von Edge Computing sind Smart Meter. Smart Meter sind intelligente Stromzähler, die durch Messungen in kurzen Zeitabständen eine große Menge an Daten produzieren. Mithilfe von Edge Computing, in diesem Fall durch die eingebettete Lösung, können Daten reduziert werden, bevor sie weiter über das Netzwerk transportiert werden. Mehr Informationen zu Edge Computing finden Sie in unserem kurzen Erklärfilm.
Einblick und Beispiel Fog Computing
Fog Computing ist eine Rechenschicht zwischen der Cloud und dem Edge. Edge Computing kann große Datenströme direkt an die Cloud senden. Fog Computing hingegen kann Daten von der Edge-Schicht empfangen, bevor sie die Cloud erreichen. Dann werden nur relevante Daten in der Cloud gespeichert. Gleichzeitig können die irrelevanten Daten gelöscht oder in der Fog-Schicht analysiert werden, um auf Fernzugriff zuzugreifen oder lokalisierte Lernmodelle zu informieren. Ein gutes Beispiel für Fog Computing wäre eine eingebettete Anwendung an einer Produktionslinie, bei der ein an ein Edge-Gateway angeschlossener Temperatursensor jede einzelne Sekunde die Temperatur misst. Diese Daten würden dann an die Cloud gesendet, um Temperaturspitzen zu überwachen. Stellen Sie sich vor, dass alle Temperaturmessungen jede einzelne Sekunde eines 24/7-Messzyklus an die Cloud gesendet werden. Mit einer Fog-Schicht würde das Edge-Gateway die Daten zunächst über ein lokalisiertes Netzwerk an die Fog-Schicht senden. Anhand bestimmter Parameter wird hier entschieden, ob und welche Daten an die Cloud gesendet werden. Dies reduziert den Datenverkehr. Bei einfachen Temperaturmessungen mag diese Dateneinsparung vernachlässigbar erscheinen. Doch stellen Sie sich die Auswirkungen vor, wenn diese konstanten Datenströme mit viel komplexeren Informationen oder großen Dateien wie Bildern oder Videos gefüllt wären.
Vorteile von Fog Computing
Ein Vorteil ist die Effizienz des Datenverkehrs und die Reduzierung der Latenz. Durch die Implementierung einer Fog-Schicht werden die Daten, die die Cloud für ihre spezifische eingebettete Anwendung empfängt, reduziert. Dadurch kann sie direkt auf die Daten der Fog-Schicht reagieren. Weitere Vorteile sind der geringere Speicherplatzbedarf der Cloud-Anwendung und eine schnellere Datenübertragung aufgrund des reduzierten Datenvolumens.
Nachteile von Fog Computing
Klar ist, dass Fog Computing Edge Computing nicht ersetzen kann. Allerdings kann Edge Computing auch ohne Fog Computing funktionieren. Fog Computing ist ein komplexes System, das in eine bestehende Infrastruktur integriert werden muss. Dies ist mit viel Aufwand verbunden. Somit ist Fog Computing nicht für jedes Szenario geeignet. Für einige Anwendungen können die oben genannten Vorteile jedoch attraktiv sein, wenn eine direkte Edge-to-Cloud-Datenarchitektur verwendet wird.
Unterschiede zwischen Edge Computing und Fog Computing - Funktionalitäten
Die Begriffe Fog und Edge Computing werden oft redundant verwendet. Mittlerweile gibt es jedoch eine klar definierte Abgrenzung zwischen beiden Lösungen. Demnach ist Fog Computing ein Oberbegriff für die Datenvorverarbeitung im lokalen Netzwerk, Edge Computing ist eine spezielle Form der Datenvorverarbeitung. Ein Fog-Gerät kennt alle in der Domäne vorhandenen Geräte. Bei Analysen kann auf die anderen Geräte zugegriffen und mit ihnen kommuniziert werden. Fog-Geräte können auf Basis der empfangenen Daten Entscheidungen treffen und kleine Datenmengen zwischenspeichern. Die Edge hingegen übernimmt Aufgaben wie das Filtern und Zusammenfassen von Daten. Edge-Geräte kennen sich untereinander nicht und interagieren daher auch nicht.
Bei Fog Nodes handelt es sich in der Regel um Geräte, die bereits im Netzwerk vorhanden sind. Sie sind in einer zusätzlichen Hierarchieebene zwischen den Endgeräten und der Cloud angesiedelt. Edge Computing hingegen findet direkt auf oder sogar im Endgerät statt.
Auswahl der richtigen Hard- und Software
Die Idee des Fog Computing basiert darauf, Geräte zu nutzen, die bereits im Netzwerk vorhanden sind (z. B. Industrierouter , Gateways, Server). Das heißt, spezielle Hardware ist hier nicht erforderlich. Allerdings müssen die bereits vorhandenen Geräte mit entsprechender Software in ein Fog-Netzwerk eingebunden werden. Solche Software gibt es mittlerweile von vielen Anbietern. Meist sind es die Cloud-Anbieter selbst, die Softwarelösungen für die Vernetzung von der Fog-Ebene bis in die jeweilige Cloud bereitstellen.
Edge Computing hingegen basiert zumeist auf Hardware. Auf vielen Endgeräten werden die oben genannten Edge Computing Funktionen ausgeführt. Diese sind in bestehende Systeme eingebettet und werden vom Hersteller bereitgestellt. Sollen die Daten eines Endgerätes ohne derartige Funktionalität am Edge verarbeitet werden, ist zusätzliche Hardware wie beispielsweise ein Edge Gateway erforderlich. Die Geräte verfügen über verschiedenste Schnittstellen, um unterschiedliche Endgeräte anzubinden.
Was die notwendige Hardware bzw. den Typ des Industrierechners angeht, kann ein Edge Gateway durchaus für den gleichen Zweck wie ein Fog-Server eingesetzt werden. Der Grund hierfür ist, dass es Unterschiede bei der Datenerfassung und -verarbeitung gibt, nicht aber bei den Funktionen und Fähigkeiten der Hardware.